Becoming Sponge: Sustaining Practice Through Protocols of Web Publishing
Michael Murtaugh
February 2022

Sponges, the members of the phylum Porifera (/pəˈrɪfərə/; meaning “pore bearer”), are a basal Metazoa (animal) clade as a sister of the Diploblasts. They are multicellular organisms that have bodies full of pores and channels allowing water to circulate through them, consisting of jelly-like mesohyl sandwiched between two thin layers of cells. Image: National Oceanic and Atmospheric Administration, Twilight Zone Expedition Team, 2007. Public domain (CC by 2.0). Source: https://en.wikipedia.org/wiki/Sponge.
Digital snapshots, audio recordings, screen grabs, recorded video streams, radio programs, posters, publications, mind maps: for 20 years dribs and drabs of digital detritus have washed ashore the various servers of Constant. Over the last three years, together with Martino Morandi, Femke Snelting, and other members of Constant, we have worked on what we call the sponge, an ecosystem of tools to index, link, and rewrite these digital materials to tell (new) stories of more than two decades of activities.
Feminist Infrastructure
The work of Constant leaves traces that are quite distributed and diverse in forms: (project-specific) websites, print and digital paginated publications, photos and other forms of audio/video documentation, and code. These traces are often distributed across different servers and (content management) systems; the “main” website (called by the Constant team “the SPIP,” referring to the name of the content management system undergirding it), a photo gallery, “pads” or collectively editable documents using another free software called etherpad, a version control repository, various blogs, wikis, and “dumps” of files often produced and collected during worksessions and typically made available via the simple “directory listing” mechanism of a web server. As often occurs with digital archives, these systems may become folded in on themselves in sort of fractal histories; multiple parallel versions of the main website exist that maintain partial documentation of specific events in the history of Constant.
As part of its ongoing work exploring the importance of infrastructure, we search for forms of ongoingness; ways to explore the feminist potential of free software, practices of maintenance, short and longer time frames, and how technology both produces norms and marginalizes. Despite “father of the web” Tim Berners-Lee’s early imploration that cool URIs don’t change, the gossamer nature of the web’s suggested materiality correctly reflects its often ephemeral and fragile nature. Keeping websites working is real work where one must often seek graceful ways to maintain sites and servers given the limits of (human) resources.
A Web Built on Bridging Practices and Protocols
Berners-Lee’s eventual choice of the name “World Wide Web” for his proposal for a new “information management” system deemed by his boss “vague but exciting,” employed a natural metaphor that would lead to imaginations of a “distributed hypertext” inhabited by spiders and crawlers. The image of a rhizomatic structure as an alternative to the strict hierarchy of the “tree” also seemed to resonate with challenges to traditional notions of authorship and copyright. A practical part of what made Berners-Lee’s web so successful – commanding both the imagination and adoption of it over a number of other coexisting hypertext systems – was the way it bridged already existing practices and protocols.

Tim Berners-Lee (CERN), “Information Management: A Proposal,” March 1989/May 1990, available at: https://www.w3.org/History/1989/proposal.html.
In the proposal, Berners-Lee imagined “gateway” servers that would “generate a hypertext view of an existing database.” While gateways provided one kind of bridge, the eventual design of URLs (those “Universal Resource Locators”) would go a step further by allowing direct references to resources across both extant and yet to be specified future protocols anticipating browser software able to negotiate (or delegate) the different links.

A list of URL schemes (protocols) including the web’s own HTTP: https://www.ietf.org/rfc/rfc1738.txt.
As history would prove, the ability to publish documents with prose text mixed with “hot words” that would access resources with a single click was, as technologists like to say, disruptive. It created a new kind of networked reading characterized by informal and contextual discovery: browsing. Parallel to this was a new writing practice where writing with links gave exposure to previously obscure resources. Indeed, early popular websites were often those that provided comprehensive links to available resources on a particular subject, contextualized by its writers. In this way sites could be seen as portals for viewing the web via the perspective of a particular theme or community. In addition, deliberate linking strategies like webrings emerged as a means of expressing solidarity between individuals and groups through web publishing.
Ironically, HTTP’s popularity in practice led to its effectively killing some of the very protocols it embraced. Google would again later disrupt web practices by creating an indexing scheme based on an analysis of the linking structure of the web, thereby also first profiting from the practices of portals and webrings and subsequently making them less visible. Given this pattern of destructive appropriation, a crucial question becomes how to design and use technical protocols in a way that values adjacent practices, sustaining and nourishing rather than undermining them.
(Avoiding) the Trap of the New Site
Editorial work with institutional websites often follows a certain pattern: the initial happiness with the new possibilities of a content management system giving way to minor inconvenience and the learning of “workarounds,” leading to dreams of a new design with new possibilities and then a final jump into the “brand new site.” Often things get lost in the jump. Previous site content can break in a myriad of ways. Specializations get dropped in the often lossy process of cut and paste. Previous design decisions may make elements look out of place, broken, or “low res” in the new frame. And all that doesn’t fit the new mold falls to the side, unsearchable, unlinked, with the totalizing logic of the new site inadvertently marginalizing older resources as no longer active or relevant. Aspects of workflow may be lost with perhaps a delayed realization that the restrictions of the “old system” weren’t so bad after all.
Back end of “The (Constant) SPIP.”
When we set out to start the work of updating the site to better reflect the distributed nature of Constant’s activities, we realized that the current editorial environment provided by “the SPIP” in fact served an important purpose quite well. It allowed the core members of the Constant team to write and maintain a set of short descriptions of each project and event, and to do so in the three working languages of Constant (French, Flemish, and English). Typically this writing occurs prospectively when planning the events. What didn’t work well was updating these articles to reflect the “life” of the events after the fact; to have ways to weave the different resulting materials together. How could the editorial work be shared and the circle expanded to include the participants of worksessions or other invited guests after the events? How to index, link, and rewrite these digital materials to tell (new) stories of more than two decades of activities?
Radical Solidarity Struggles
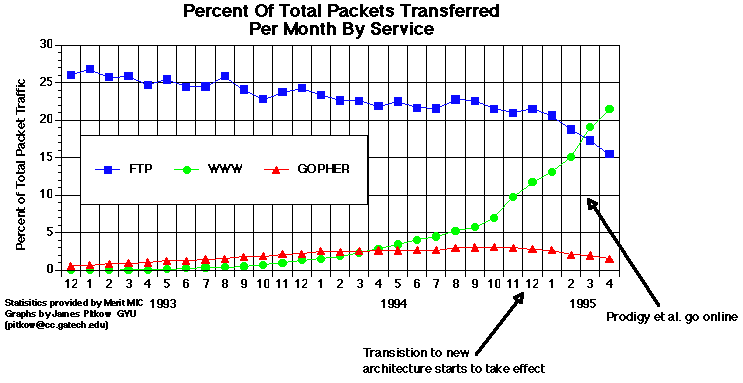
The technical protocol RSS has a complex and conflicted history, the messiness of which springs into view when simply trying to unpack what the letters stand for: RDF Site Summary, Rich Site Summary, Really Simple Syndication. All of these names have been claimed at different times and by different parties as the protocol’s rightful identity. The core idea with RSS is to define a standard way for websites to announce their contents for the purpose of aggregation. Users of an aggregator might subscribe to RSS feeds of interest and the software will periodically check the feeds and pull in new stories to present to the user in a unified interface.
Discussions of technical protocols are contentious as the alignment of such protocols with certain practices normalizes those while marginalizing others. For instance, in version 0.92, the addition of “enclosures” to the standard enabled audio content to be included in feeds enabling the rise of what’s popularly known today as podcasting. Thus, a protocol (borne from technical blogging) gets picked up by a rising browser company (briefly) interested in the nascent business of web portals, to then fork a year later into two competing standards – with one community attempting to reduce the complexity of the standard to stay more closely aligned with blogging and another steering the protocol “back to its roots” as a general-purpose tool to classify the diversity of an entire site’s contents. In the end, the bloggers attempt to leapfrog the others by announcing themselves a “2.0” version of a “really simple” protocol all about “syndication.” In the meantime, prominent ridicule of the struggles of the protocol helped to fuel the development and adoption of another parallel competing standard that would also garner support from big players like Google.
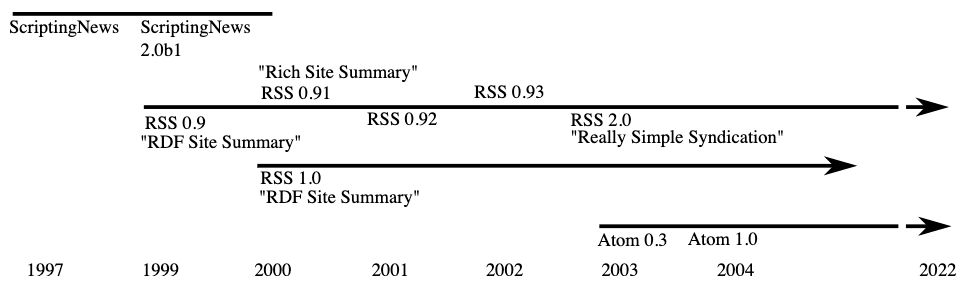
Timeline based on one appearing in Michael P. Sauers, Blogging and RSS: A Librarian’s Guide (Information Today, 2010).
In 2006, Twitter announced itself as a “micro-blogging” site. In another case of embrace, extend, and extinguish, Twitter initially made extensive use of RSS, allowing the service to co-occupy a space with other blogging practices. By 2013, with a deeply established base of users, the service “upgraded their API,” dropping its RSS feeds and following an industry trend to only offer feeds or other structured data via an “authenticated API.” This means that aggregators not only need to include Twitter-specific code but also need to use a so-called API key: a user-specific password given in response to an individual (click) signing a legal agreement stipulating that if the terms of the API are not followed, the key can be revoked. In other words, protocols designed literally to feed a distributed community of practice are replaced by the lock and key logic of non-negotiable terms protecting the interests of increasingly centralized and commercial services.
Becoming Sponge
A particular feature of SPIP is its ability to aggregate RSS feeds. So, in addition to generating outward facing RSS feeds announcing the articles published on it, the software allows editors to “follow” external feeds and the system maintains copies of the collected material. This feature is still visible in the current Constant website under the section Signals, which displays short descriptions and links to activity from these incoming feeds.
Inspired by this functionality but also frustrated with its limitations, a first key decision was to say that the “new site” would be a frame displaying the existing site alongside related materials aggregated or indexed from the larger network. Martino began to refer to this framing system as the sponge, a metaphor that strongly resonated with an ecological approach of caring for what you already have and that helped focus the understanding of the work.
In doing the work, we made use of RDF (that first sense of “R” in RSS), which stands for Resource Description Framework. RDF is an alternative to a traditional (tabular) database structure that, following the web, expresses data as relationships between nodes in a network. In practice, a key implication is that whereas in a traditional database the relationships are fixed and decided when the system is developed, an RDF “store” (or index) can accommodate new relationships. In this way, the relationships can literally be rewritten over time.
The shift to indexing externally written documents allowed work to proceed in multiple parallel interventions. The sponge combines practices of web spidering and crawling with scraping, translating loose or informally structured material into descriptions that converge or aggregate in ways relevant to a locally defined vocabulary.
In the description of our photo gallery, editors would sometimes paste links to SPIP pages of related events and projects. We activated this practice by having scripts periodically read from the gallery and treat these links as “tags” to be applied to the images. Once indexed, visitors to a particular project description page (from the SPIP) are presented with clickable thumbnails of the images so linked from the gallery. We similarly activated the simple directory listings of audio and video files to support tagging with pages from the SPIP site. In this case, we used a format called RDFa that permits the aggregatable descriptions to be directly written into the contents of a web page.
Finally, as part of the maintenance and archiving work, we started to use scripts to translate certain projects into static snapshots. In the process, descriptions can be added, allowing another means of weaving past projects into the site while also stabilizing the projects – as the copies allow code and databases to be taken offline so that they are no longer in need of day-to-day maintenance.
Resisting the Call of “Raw Data Now!”
Without fully knowing it, we were, in fact, engaging in a set of practices already associated with the name “sponge,” techniques to bridge and adapt extant materials to aggregatable descriptions. In 2009, Tim Berners-Lee took the stage at the TED conference in Long Beach, California, and led the audience to repeatedly chant the words “Raw Data Now!” The pitch was part of a larger effort promoting a vision of “linked open data,” encouraging institutions to not only publish web pages online but to also make diverse kinds of “data” available in a format that would allow for aggregation. In this vision, RDF serves as the centerpiece of the so-called “Semantic Web.”
One problem with Berners-Lee’s chant, unresolved by simply “exposing” the databases of the world, is the idea that data can somehow be “raw,” an extractivist mentality that imagines diverse knowledge reducible to elements that can be distilled and made valuable purely by automated processing. Demanding “raw data” is an oversimplification that imagines the alignment of different practices to a shared vocabulary as something trivial.
Another problem, manifest in the strangely petulant tone of his plea, is the presumption that all the data of the world should be released, with no discussion of why or for whose benefit, no consideration of past examples of commodification of materials generated with care by communities, and no consideration of the implications for reuse.
Here again, the familiar “vague but exciting” air of technology for technology’s sake demands the reminder that protocols – in the dual sense of social and technical – are political. In choosing to work with standard protocols, we are explicit in doing so with an opposing set of values that talk back to the power structures involved.
Warping and Wefting
A final, crucial part of our work was another example of activating already existing practices within Constant, namely, the use of etherpads. A F/LOSS collaborative document-editing software with its own particular history, etherpad’s real-time nature and freeform use of text supports a surprising variety of collaborative activities: writing, editing, and planning. A specific part of my work in fact had been the development of software to manage making periodic archival copies of the pads, as well as a portable installation for use in worksessions.
As part of the move away from using the “keywords” features of SPIP, we imagined the writing of new kinds of documents that we call Warps and Wefts, terms borrowed from weaving. The aim was to open up the editorial process as much as possible and, in a way, return to the practices of writing with links so prevalent in early web work. In translating the pads into HTML documents, RDFa is used to activate the links in particular ways for use with the site index. With Wefts, the document itself acts as a tag applied to all of the links in the document. Thus, the Cyber Feminism weft bridges both internal and external nodes within the larger Constant network. Warps work in a similar way but instead act as proxies for an already existing page, allowing new links to be woven into an existing project. As visitors view pages on the Constant site, related Warps and Wefts appear alongside.

An installation in the window of the Constant office; the sponge was used to collage photos, videos, and textual descriptions from the history of Constant.
Protocols to Sustain Practice
Sponges have unspecialized cells that can transform into other types and that often migrate between the main cell layers and the mesohyl in the process. Sponges do not have nervous, digestive, or circulatory systems. Instead, most rely on maintaining a constant water flow through their bodies to obtain food and oxygen and to remove wastes. Sponges were first to branch off the evolutionary tree from the last common ancestor of all animals, making them the sister group of all other animals.
In our work maintaining the infrastructure of Constant web publishing, we find inspiration in the figure of the sponge.
Sponges are porous.
We engage with “bridging” protocols that honor the complexity of diverse practices (library sciences, informatics, archival practices, writing, and the intersectionality that feminisms bring to each), and engage with standards while maintaining our own terms.
Sponges are slow.
Our work resists the ruptures of the “new,” preferring care; graceful forms of maintenance given limited resources and continuity. Our work embraces historically established protocols (like RSS) and practices (such as writing with links and webrings). We believe in institutions caring for their data and embrace tools and workflows that don’t create an either-or choice between a refreshed design and preserving the deep history of an institution as reflected by their web publishing.
Sponges live through circulation with their environment.
Our work recognizes protocols as political and rejects the toxicity of extractivist practices, destructive appropriation, and the lock and key model of access. Instead, we take a considered approach to what circulation means and who it might benefit or harm. We seek forms of work that function as soft filters rather than templates, embrace freeform formats and ways of working that avoid becoming calcified and prescriptive, and activate protocols that solidify and amplify practices in a responsive way while maintaining locally defined values. We look for convivial ways to index, link, and rewrite (new) stories and publish them in a way that sustains both our own work and the members of a network of individuals and institutions with whom we work in solidarity.
Copyleft 2022 Michael Murtaugh. You may copy, distribute and modify this material according to the terms of the Collective Conditions for Re-Use (CC4r) 1.0.
Michael Murtaugh is a member and co-system administrator of Constant and director of the Experimental Publishing master course (XPUB) at Piet Zwart Institute in Rotterdam.