Beyond Follows: Trust In Computing
Sarah Friend
May 2022
Trust is a felt quality of human relations, ephemeral and changing. To turn trust into data might seem wrong, like pinning the butterfly – but the butterfly is getting pinned all the time. When you follow someone on Twitter or upvote someone’s post on Reddit, semantically these are both small gestures of trust for the person being followed or for the post. To parrot Guy Debord, social media is not a series of interactions with technology, it is a social relation among people, mediated by technology.1 Social media is an attempt to extend real sociality and to represent real trust. Routine actions – the follow, the five-star rating – can all be thought of as indicating kinds of trust which are modeled behind the screen as data. What is the shape of this data? Usually, it looks like a web or network. In computer science, it’s called a graph.
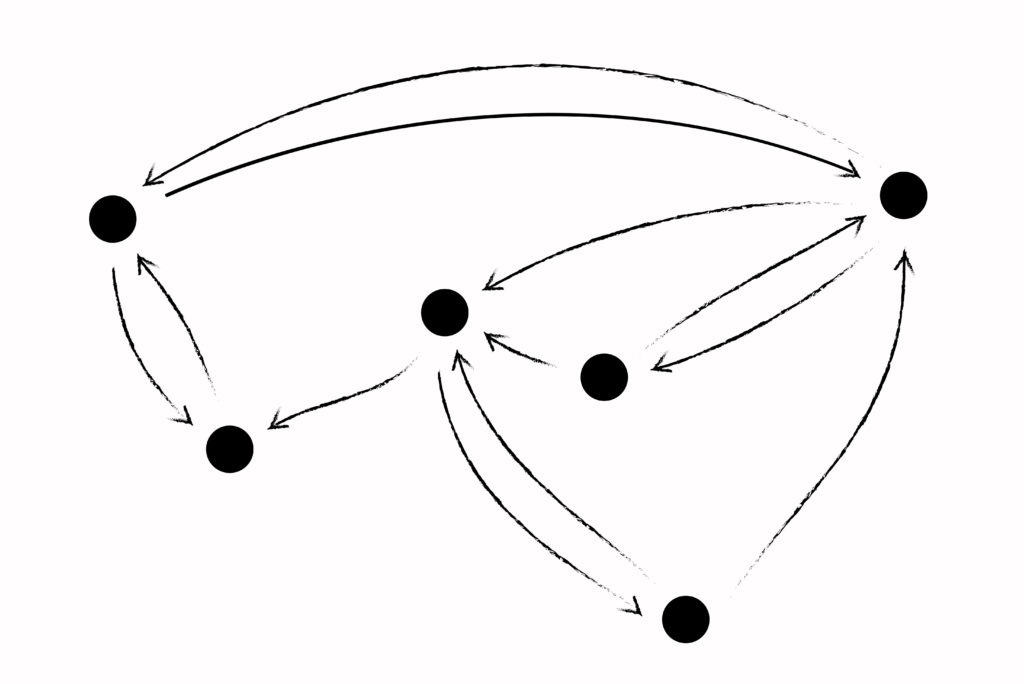
Networks contain nodes, which usually map onto accounts or people or computers, depending on which network we’re dealing with. On Twitter, these nodes would be accounts. On a blockchain, they would be mining computers. These nodes are connected by lines representing trust. Networks like these underlie many commonly used platforms, but the implementations are subtly different and have different affordances. Many of these networks attempt to capture social relationships or trust, a process that always maps imperfectly to lived experience. But by looking at the network structure itself, we can recognize patterns that emerge across different technological contexts, leading to better models and a better understanding of the trade-offs being made. Despite the challenge of turning the ephemeral into the mechanical that goes along with building a model of trust in data, the possibilities may prove worth the difficulty.
Let’s start with the carrot instead of the stick. For a long time, I worked on a project called Circles UBI (UBI standing for universal basic income). Circles UBI is an alternative currency that has mechanisms that lead to a more equal distribution of wealth over time. It’s not a universal basic income in the typical sense, where a state redistributes money, but it shares common goals with those projects. Much like the state-based UBI, it needs a concept of identity: a way to assure the uniqueness of persons and minimize the chances of someone unfairly collecting UBI twice. In the state-based system, that is usually done by some form of government-issued ID. This presents problems of access for migrants, stateless people, etc., but it is still the way most state-based UBI is designed. In Circles, a system trying to accomplish similar goals in the absence of a state or central authority, a different approach is needed. The solution it has used is a trust network much like the one above. Let’s look more closely at their structure.
Above is a drawing of a trust network, but that image already contains several assumptions. One of them is that trust has a direction: I trust you, but you do not necessarily trust me back. This is the kind of trust network that exists on Twitter or Instagram with followers and following. Me following you is a trust connection with a direction, an arrow going from me to you. In the early days of social media, on Myspace and the first iterations of Facebook, the opposite structure was used: an indirect or always reciprocal model of trust. You could not be my friend unless I friended you back. Here’s an image of what that network might look like:
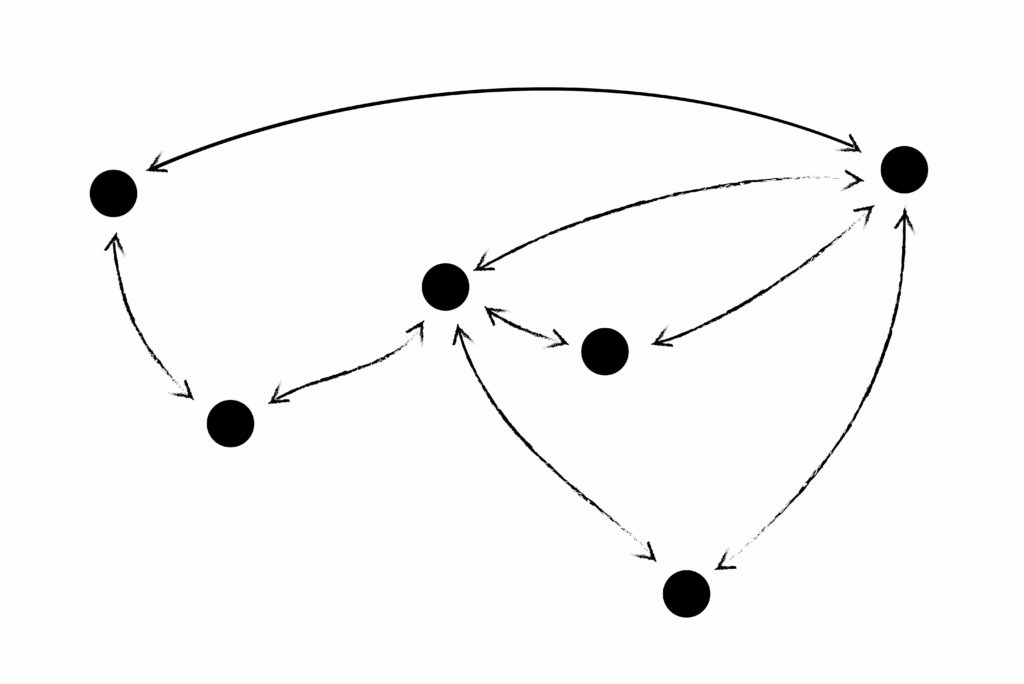
This is subtle, but significant. What has changed about us as people using the internet that leads from reciprocal to directed trust? When we see reciprocal trust in platforms created more recently, it is often because they make no attempt at being publicly browsable. Trust is still treated as reciprocal when we imagine the accounts we’re trusting as contacts; they map loosely onto “people” (i.e., accounts) and are treated like an online extension of who we know in real life. Trust is directed when we have shifted from trusting people to trusting information (or wanting to see content) shared by people. The shift from trusting people to trusting information, and from reciprocal to directed trust, may lead to increasing inequality in the distribution of attention. Is this causal or symptomatic to any of the great cultural woes of past years? Reciprocal trust is limited by the human capacity to know and remember other people. Reflecting this, Facebook, at least, still artificially caps friends at five thousand. To have more inbound connections, one must start a page that has followers not friends, and enter the world of directed trust.
Another assumption made in both diagrams so far is that trust is binary, meaning trust is either present or it is not. With this model, there is no gray middle ground of trust, and the platform allows no expressive potential for the quality of trust. We see binary trust on most major social media networks. I either follow you or I do not. The alternative is weighted trust, which most people are familiar with in the context of a rating system. When you give your Uber driver five stars, besides committing a small humane gesture, you are also expressing your level of trust – not in them as a person overall, but in their ability to provide a safe, satisfactory ride, and you are giving that trust a weight between one and five stars. Here’s an example of what a weighted trust network might look like, imagining trusts as percentages.
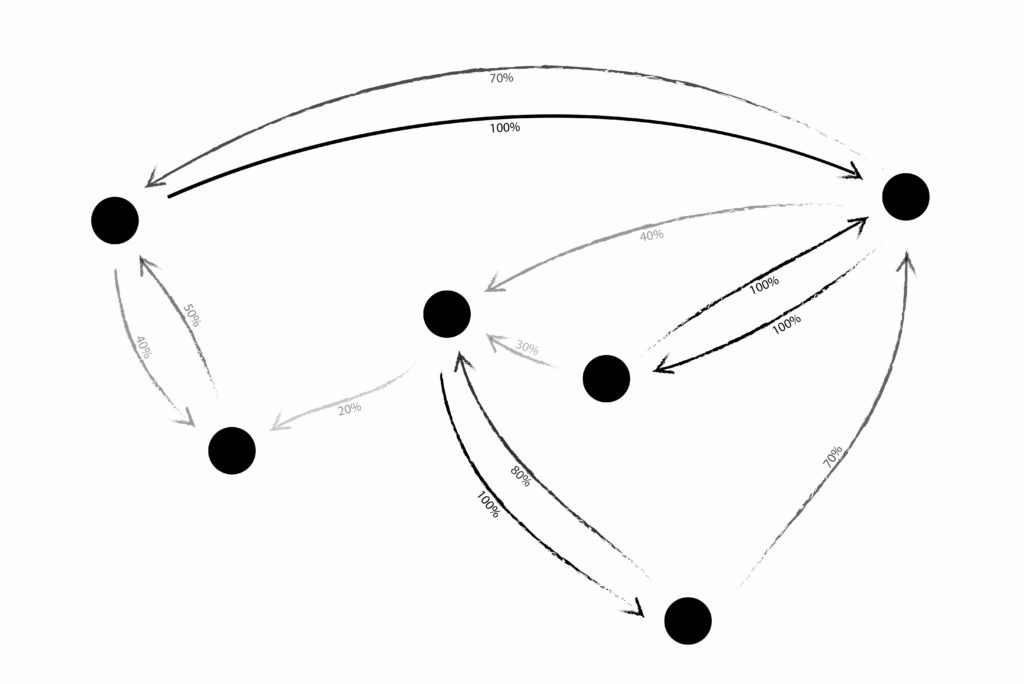
Possibly the oldest formalized example of a weighted trust network is also one of the oldest formalized trust networks, period. It’s called the web of trust and originated with PGP. Created in 1991, PGP stands for Pretty Good Privacy and is a tool for encrypting messages like emails. It was designed to be able to keep communication secret without a central authority to verify identity and therefore aid trust. This is extremely similar to the question introduced above with Circles UBI. In PGP, the answer was a public communal trust network. This web of trust allows everyone to see who is trusted, and by whom, so they can better make decisions about which accounts to trust themselves.
Typically, the web of trust is bootstrapped by attendees of events called key-signing parties. These are in-person events where participants attend with information about their PGP accounts and whatever proofs of identity the key-signing-party participants have decided to accept. Usually, despite trying to operate in a decentralized way, key-signing parties use government-issued IDs, but alternative systems are possible. Taking turns, each person seeking inclusion proves that they own the account, which is a set of cryptographic keys that they are claiming to own. The other users then use their own keys to sign the key of the person seeking inclusion – these collected signatures are like the connecting lines on the network diagram, pointing from one node to another. Structurally speaking, they are the same as the familiar followers/following connections on other platforms. The signatures are then posted online where they can be publicly accessed.
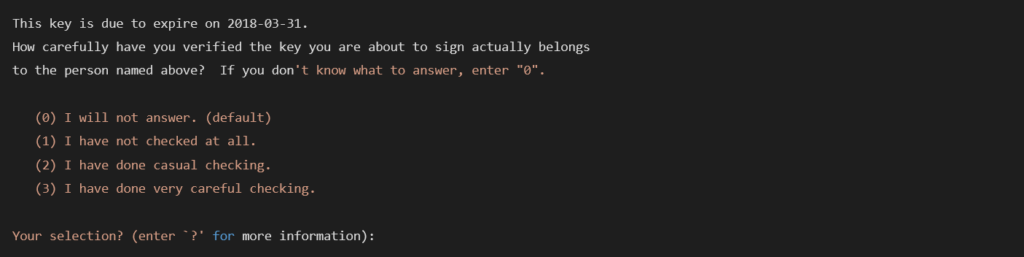
Additionally, when signing the key of another user and indicating that you trust them, you can assign it a public “certification level.” The certification level is intended as an indicator of how thoroughly you have checked the identity of the person whose key you’re signing.
Here’s an example of PGP’s default certification levels:
Jeff Carouth, “Signing PGP Keys,” May 25, 2014, https://carouth.com/articles/signing-pgp-keys/.
PGP has another kind of trust level that is also weighted. This one is literally called the “trust level,” and it governs the transitiveness of trust. Transitiveness refers to whether trust is passed along through the connections of the network. For example, if I trust you, do I also trust the people you trust? Or do I trust them less than I trust you, but still a little? How many levels outward does my trust ripple before it has fully dissipated? In PGP, I would assign you a high certification level if I had vigorously checked your identity, but I would assign you a high trust level if I believed you were highly competent at validating the claims of others. This may seem unnecessarily complicated – and, indeed, poor usability is often earmarked as one of the reasons PGP has not become a more widespread protocol – but the possibilities of weighted trust, transitive trust, and differentiating kinds or qualities of trust are all important distinctions that may be present in any trust network.
Let’s return again to a rating system similar to the ones you’ve encountered with gig economy platforms like Uber, or large marketplaces like eBay. You may have personally rated a given driver five stars, and someone else may have given them four, but that’s not how the data is presented. Instead, you see an overall score of 4.89, which is a compound score calculated from the many connections in the network. One of these connections goes from you to the driver, but there are a hundred others, all from other passengers to the driver. The overall rating is a global, or system-wide, trust score, calculated over the network as a whole.
Besides star-based reputation scores, another much less explicit but perhaps more powerful place we see a global trust score is Google PageRank, which is the first and most well-known algorithm that Google has used to search results. Defined in 1996 by Google founders Larry Page and Sergey Brin at Stanford University, PageRank calculates the “importance” of a given website through the quality and quantity of inbound links to it. These inbound links are just another form of the inbound arrows in the network diagram: a connection from one website to another that has a direction.
How might one calculate a global trust score? The simplest way would be to add up all the records of inbound trust and find an average, but this would be easy to manipulate. In the case of PageRank, that could look like creating thousands of simple web pages that do nothing but link back to a page you’re trying to boost. Attempts to hijack a network and artificially inflate the seeming importance of one node are called, in the general form, Sybil attacks. Any system that wants to use a global trust score must have defenses against them. Many platforms use friction during account creation, like confirming an email or phone number. Another approach is to weigh the importance of an inbound trust connection by the importance of the trust-giver. PageRank, for example, considers quality links to be those from sites that themselves have a high PageRank score, meaning that my one thousand fake websites, which could at best link to one another, would have a difficult time shifting the numbers.
Sybil attacks are the reason some blockchains use energy-intensive mining algorithms, or proof of work. The high energy use makes the creation of many “fake” identities useless, since ability to control the network isn’t tied to the quantity of fake identities but instead to their computational power, which has a material cost. While there are, of course, environmental externalities outside the scope of this article and also alternate solutions to the Sybil problem, proof of work is one of the ways to make this kind of attack prohibitively expensive.
It’s also worth considering whether a global trust score is desirable or useful. The word “global” here means spanning a whole network. Its opposite, as when we’re talking about geography, is local. Each node in a network has a location and a local view of trust. We can think of the utility of shifting between global and local as a question about “how transitive we think trust is” and, secondarily, what kinds of subjectivities are involved in the network’s particular semantic meaning of trust.
There are systems where there is less, or even no, personalization involved in trust. For example, one well-known method of calculating a global trust score, called Eigentrust, was designed as a way to manage reputation in a peer-to-peer (P2P) file-sharing network. In the context of Eigentrust, a node is a computer, and it is considered trusted if it reliably returns the requested files. It could be implemented by BitTorrent clients without the user being aware of subjective “trust” at all. But there are other contexts where, if trust stops being personal, it becomes meaningless. Consider the example given by Jennifer Golbeck, in her paper “Computing with Trust: Definition, Properties, and Algorithms,” of a system for determining what information is considered trustworthy.2 In the polarized political climate of the United States, how would someone as divisive as Donald Trump score? His global trust score would come in somewhere in the middle, with some subset of people saying he is highly trustworthy and others saying he is extremely untrustworthy. This may be “correct,” at least as an impersonal metric for how likely one of his statements is to be true (and to avoid the more difficult questions about the possible objectiveness of information). But it would be useless in terms of actually understanding the shape of trust around Donald Trump, and, more practically, recommending content that might be of interest to any given social media user. This example itself is, of course, also polarizing and perhaps easy to dismiss, but this effect would not only lead to useless ratings of politicians you may dislike. The same effect could also distort results for minorities and people who experience prejudices, or flatten anything sufficiently subcultural.
It seems possible that too much globality in terms of trust leads to loss of granularity and silencing of difference, and too much locality leads to a disturbing filter-bubble effect. Some questions: Is a possible mitigator of polarization to make trust more transitive? And more philosophically, is the concept of a global trust score in some ways always embedding a singular concept of truth into the systems that use it?
So, after exploring a few aspects of how we might model trust in computing and its unfolding complexity, let’s return to the example of Circles UBI. Circles UBI needs to protect the users against Sybil attacks wildly distorting the monetary supply. It does this with a trust network. When a person signs up for Circles, they actually create their own personal currency, which is tied to their account. They then make connections to people they trust and only accept coins from those people. Thus, even if there is a large pool of fake Sybil accounts, it won’t hurt them because they’re unlikely to trust those fake accounts. But, of course, it’s difficult to build a working monetary system if you only ever transact with people you know directly. In practice, only very few things are bought directly from people we know. That’s why Circles also passes coins through the trust network transitively. Here’s how it works:
![]()
In Circles, trust is directed – I can trust you without you needing to trust me back – and weighted – I could trust you 0 percent, 43 percent, or 92 percent. Trust is transitive, though it’s not transitive in the sense that if I trust you, I implicitly trust people you trust, but that we pass coins along the transitive paths. The Circles system is complex (and in particular our choice to use weighted instead of binary trust greatly complicated development efforts and may be changed in a future version), but it’s also a fascinating application of trust networks and decentralization to a social problem.
Here’s another one: One of the thorniest problems for decentralized protocols is content moderation. In the absence of a company to set policy, or a government to define hate speech legislation, who decides what is acceptable content? Can harmful content be identified without the creation of a central group of moderators? One interesting approach to this is found in Secure Scuttlebutt. Secure Scuttlebutt, or SSB, is a decentralized social network where people blog and post status updates, jokes, and pet pics. Like many social networks, in SSB users follow those they trust. What is more unusual is that they only see content from people who are within a few transitive “hops” from them in the trust network. This parameter is configurable but usually defaults to around three. Because content passes transitively through trust, you can also see how it got to you, following the path the content took to get to you and disconnecting from that section of the trust network if you don’t like it, like trimming a hedge. In SSB, trust is directed, binary, and transitive for a few hops. The limited transitivity of trust in SSB already results in something like content moderation, as well as transparency and insights into your social surroundings in terms of how the content you see is shaped. But it can be imagined even farther. For example, Alexander Cobleigh’s TrustNet uses a weighted trust network to calculate a trust score somewhere between global and local (three to six transitive hops) and uses this to build a set of content moderation peers.
There are alternative taxonomies for trust networks than the ones I’ve used here, and many further examples of interesting constructions for different use cases, such as the concept of a strong set, also implemented in PGP, or the Duniter Web of Trust. Learning to think about and see networks underlying platforms and interfaces can elucidate their secret underbelly and allow generalizations across contexts. In short, there are many kinds of human and social questions that spiral out from the quantitative choices of what trust looks like in a particular application – and just because a particular pattern is familiar in one context doesn’t mean it is benevolent or can be usefully applied elsewhere.
This essay has been published in partnership with Berliner Gesellschaft für Neue Musik (Berlin New Music Society) for Process and Protocol, a weekend-long festival at ACUD Macht Neu (April 1-3, 2022) that explored the potential of Web3 and blockchains for experimental musicians and composers.
Footnotes
- Guy Debord, Society of the Spectacle, trans. Ken Knabb (Berkeley: Bureau of Public Secrets, 2014), 2, https://libcom.org/files/The%20Society%20of%20the%20Spectacle%20Annotated%20Edition.pdf
- Jennifer Golbeck, “Computing with Trust: Definition, Properties, and Algorithms,” 2006 Securecomm and Workshops (2006): 1–7, https://doi.org/10.1109/SECCOMW.2006.359579.
Sarah Friend is an artist and software engineer specializing in blockchain and the P2P web. She is a participant in the Berlin Program for Artists; a co-curator of Ender Gallery, an artist residency taking place inside the game Minecraft; an alum of the Recurse Center; and an organizer of Our Networks, a conference on all aspects of the distributed web. She has been working in the blockchain industry for over five years, from the perspective of both an artist and a software developer at one of the largest blockchain companies in the world. She is on the advisory board of Circles UBI, an alternative currency that tries to create more equal distributions of wealth. Recently, she has exhibited work at the Illingworth Kerr Gallery in Canada, Kunstverein Hamburg, OÖ Kultur in Linz, Galerie Nagel Draxler in Cologne, suns.works in Zurich, and Floating University in Berlin.